InstructZero: Efficient Instruction Optimization for Black-Box Large Language Models
University of Maryland, 5 Jun 2023
数据、代码:https://github.com/Lichang-Chen/InstructZero
简介
对于不能反向传播的闭源大模型,怎么优化指令提示是一个挑战。作者没有直接优化离散的指令,而是优化输入开源大模型的低维soft prompt,以生成闭源大模型的指令。 在每次迭代中,使用开源大模型将软提示转换为指令,然后将其提交给闭源大模型进行zero-shot评估,并将评估性能输入给贝叶斯优化产生新的软提示,提高zero-shot性能。
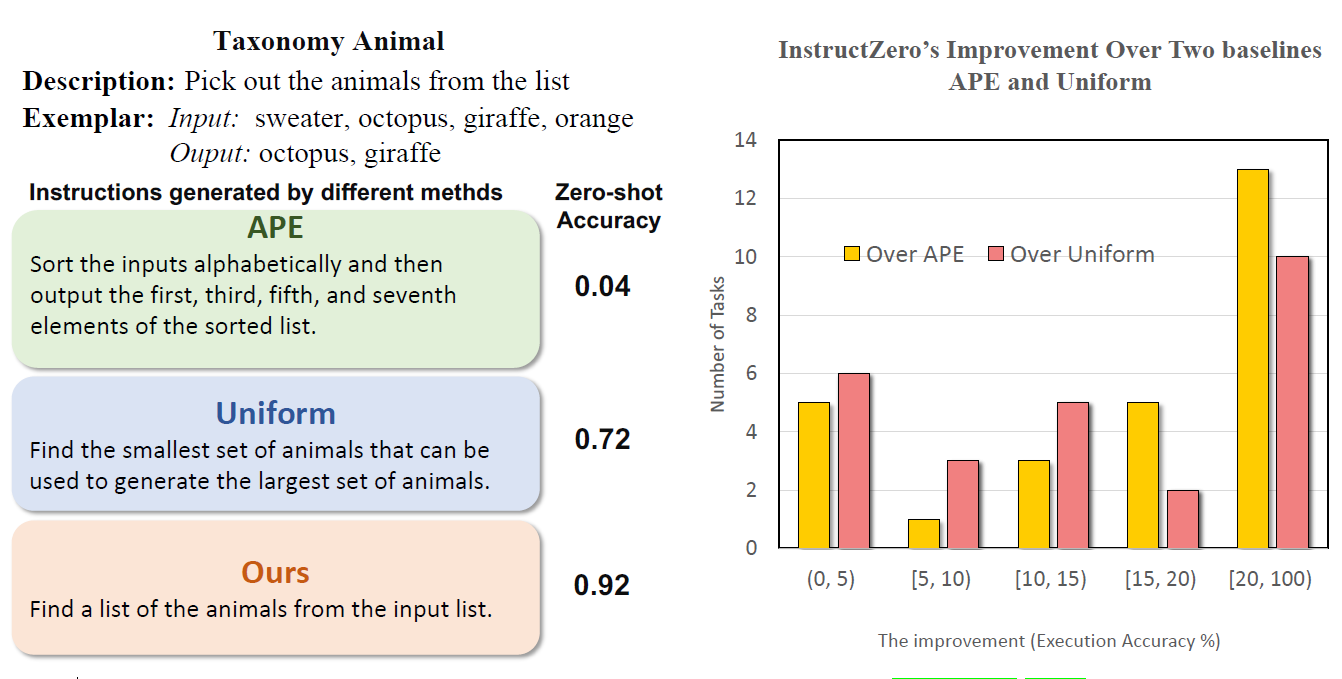 比较INSTRUCTZERO和基线方法( APE [Zhou et al., 2022] 和均匀采样(uniform sampling))
比较INSTRUCTZERO和基线方法( APE [Zhou et al., 2022] 和均匀采样(uniform sampling))
指令优化问题定义
黑盒大模型:f(⋅)
输入的query: X
指令:v∈V
评价指标:h(⋅,⋅)
真实标签:Y
优化目标,即最大化从任务t的数据分布Dt中取一个样本(X,Y)的期望分数:
v∈VmaxE(X,Y)∼Dth(f([v;X]),Y)
但是这个公式存在两个挑战:
(1)复杂结构约束的组合优化。指令v的优化空间V是高维、离散的,在语义约束下高度结构化,目前不存在这种空间进行优化的
高效算法。
(2)黑盒优化,无法直接进行方向传播。
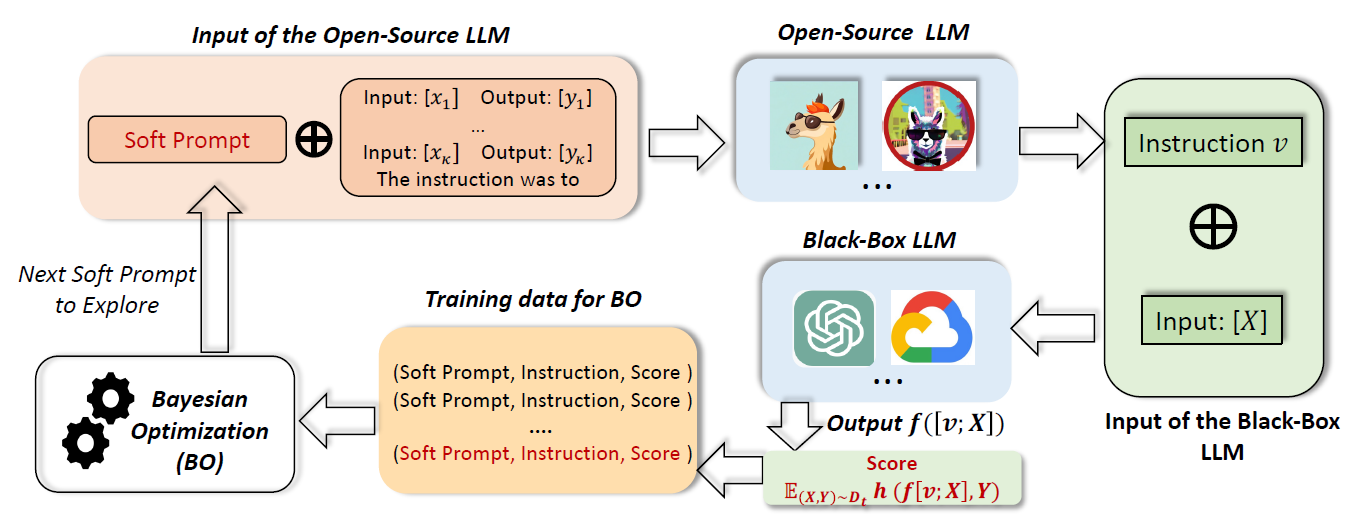
既然无法直接优化v,INSTRUCTZERO的核心思想是优化一个soft prompt p,p输入到开源大模型(LLaMa)g(⋅),通过针对目标任务的In-context learning(κ个示例),开源大模型再输出自然语言指令v。v输入到黑盒大模型产生zero-shot预测结果和性能分数用来评估期望分数,再通过贝叶斯优化(Bayesian optimization)产生新的soft prompt。
具体来说,将一个d′维的soft prompt p∈Rd′,以及κ个示例(xi,yi)i=1κ(token embedding)输入到开源大模型g(⋅),生成的指令v再输入到闭源大模型。因此组合优化问题可以被重构为一个可行的连续优化问题:
p∈Rd′maxE(X,Y)∼Dth(f([v;X]),Y), s.t. v=g([p;(xi,yi)i=1κ])
对于现在开源大模型的来说,维度太高无法直接用现有的黑盒优化方法进行处理,因此需要降维操作。INSTRUCTZERO使用一个矩阵A∈Rd×d′(高斯分布或者均匀分布初始化)将soft prompt p∈Rd映射到低维隐空间(d≪d′)。这样做的目的是:(1)根据Johnson-Lindenstrauss 引理,随机投影保留了距离,(2)通过In-context learning,低维soft prompt足以产生丰富多样且与任务相关的指令作为候选。所以问题变为最大化一个低位空间黑盒函数H(p)的最大值:
H(p)≜E(X,Y)∼Dth(f([v;X]),Y),v=g([Ap;(xi,yi)i=1κ])
基于Instruction-Coupled Kernel的贝叶斯优化
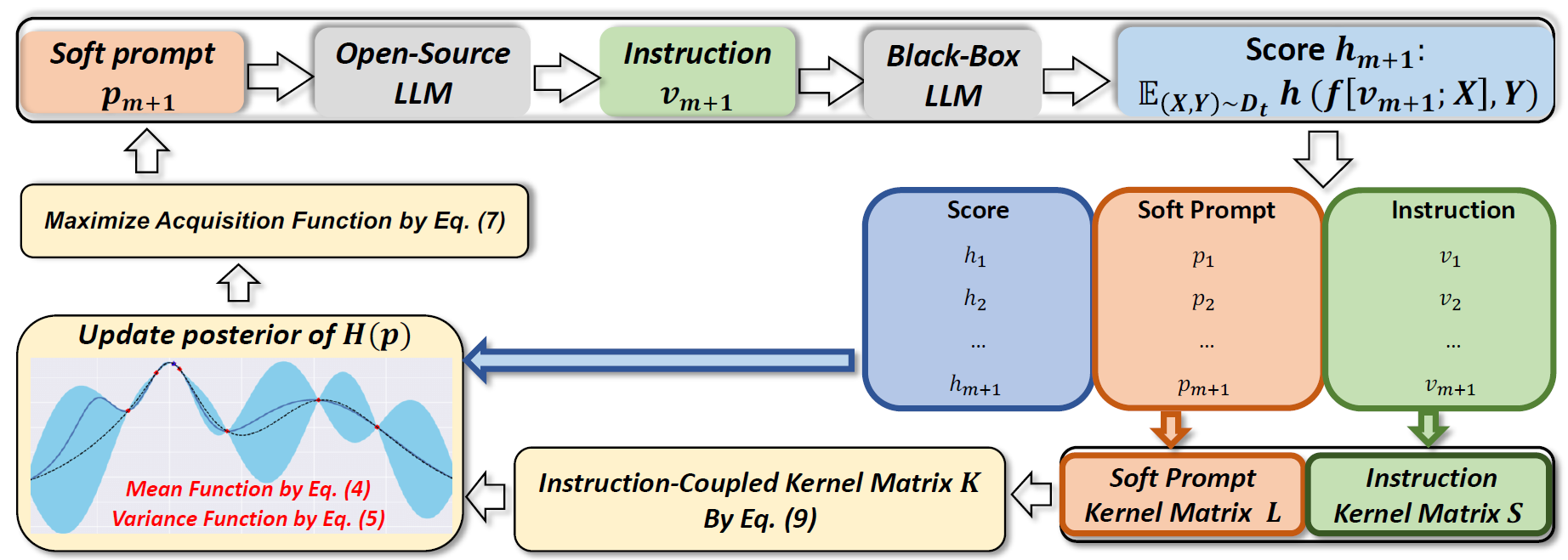
贝叶斯优化的目的是评估黑盒目标函数H(p)并找到最大值,根据收集的 (p,H(p))不断更新H(p)的后验并探索新的soft prompt ,直到H(p)收敛到最大值(评估性能分数为在验证集的平均结果)。这里使用常用的高斯过程(Gaussian Process)作为黑盒目标函数的先验。高斯过程先验可以由一个均值函数μ(⋅)和一个协方差函数(即核函数)k(⋅,⋅)确定。给定m个提示和他们的评估结果,H(⋅)的估计后验被作为一个高斯分布进行更新,其中均值函数和方差函数定义如下:
μ(p)≜k(K+η2I)−1H1:mσ2(p)≜k(p,p)−k⊤(K+η2I)−1k
K表示相应的高斯过程中的核函数计算出的协方差矩阵,I表示一个与K维度相同的单位矩阵,η是衡量观察值噪声水平的常数。预期改进获取函数 u(p)衡量候选软提示相对于最佳soft prompt在目标值方面的改进,定义如下:
u(p)=EH(p)∼N(μ(p),σ2(p))[max{0,H(p)−i∈[m]maxH(pi)}]
贝叶斯优化通过最大化u(p)来确定下一个soft prompt pm+1进行探索:
pm+1∈p∈Rdargmaxu(p)
在目标任务上两个指令zero-shot预测的相似性:
s(vi,vj)=EX∼Dt[sim(f([vi;X]),f([vj;X]))],
sim(⋅,⋅)是预测结果(例如F1分数)的相似性,核函数(Matern or Squared Exponential kernels)在soft prompt和提示上分别对应两个核矩阵(S,L),通过结合soft promt和指令的核函数进一步提出一个instruction-coupled kernel function:
Ki,j=k(pi,pj)=li⊤L−1SL−1lj